SQL Migration
Code shift point
DB2, ORACLE and MSSQL have the capacity to insert a LOW_VALUE (0-byte) value.
POSTGREQL does not allow it.
So, the code shift point mechanism has been introduced to abstract itself from this constraint.
For CHAR and VARCHAR column, it consists in transposing the control characters from the EBCDIC page code to a UTF-8 compatible page code containing 256 non-confusing characters.
These characters are transposed to the Latin Extended-B page + the first 3 lines of the International Phonetic Alphabet page. The Latin Extended-B page starts with the character LATIN SMALL LETTER B WITH STROKE, unicode point code 0180. The EBCDIC control characters are (in general for all EBCDIC page codes) on the first 16 * 4 characters + the last character.
The first character is LOW-VALUE, the last is HIGH-VALUE.
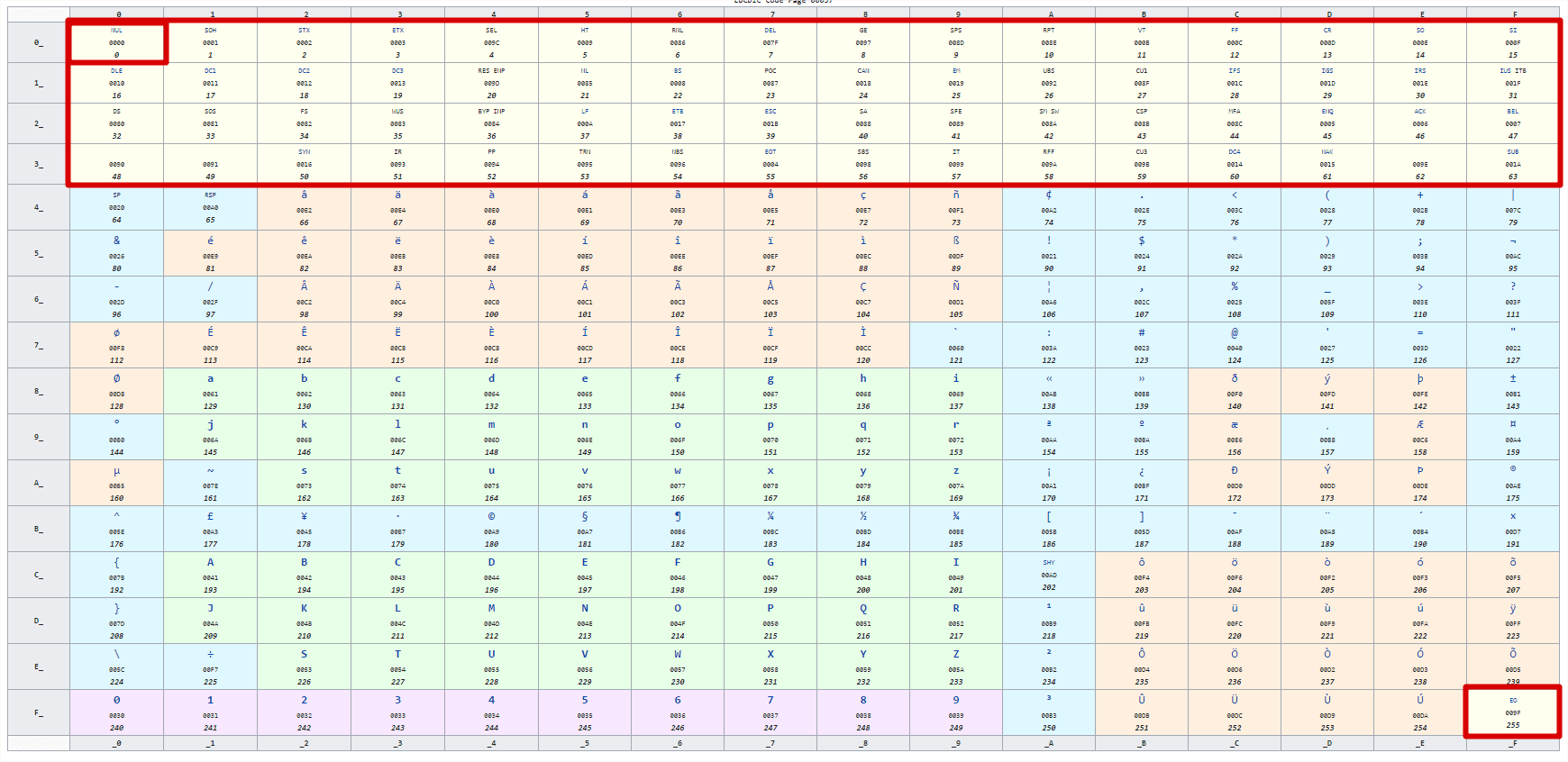

Thanks to the codeshiftpoint property set to 384, corresponding to the code point "\u0180", into the application-main.yml, the SQL Runtime is enabled to convert values at read and write steps.
Example:
The program inserts LOW-VALUE, 0-byte is converted to 0x180, the ƀ character is inserted into database.
The program reads the ƀ character, 0x180 is converted to 0-byte, the program gets 0-byte.