Advanced Options
Comparison performance
To avoid RAM issues with elements too heavy. You can use the "splitLines" and the "splitSize" options. With theses options set, the compare tool will split big elements when one of the limits is reached. "splitLines" specify a maximum record count of an element split "splitSize" specify a maximum size of an element split "compareAlgo" specify which diff algorithm to use for comparison
Algorithm Options
The tool supports multiple comparison algorithms:
- "Myers" (default): Standard Myers diff algorithm
- "Histogram": High-performance JGit-based algorithm, recommended for large files
- "BCompare": Integration with Beyond Compare external tool
- "Internal": Custom internal algorithm implementation
{
"comparisonType": "Flatfile",
"compareAlgo": "Histogram",
"splitLines": 100000,
"splitSize": 500,
"twoPassDifferences": true
} In this case, splitting with occur when 100000 rows are read, or 500 MB of data are read, whichever comes first.
Each split is considered by the tool as an independent data storage. For instance, if a file is split in three parts, the tool will compare part1 on the left and part1 on the right, and same for part2 and part3, independently.
This means that there might be corner cases, where a row with a given business key appears on the left in part1 and on the right in part2. This will appear as a difference in both parts (false positive). twoPassDifferences option may be used to prevent this. It will reconcile errors across splits. This may be RAM intensive depending on the amount of errors. (thus splitting a file and enabling twoPassComparison if there is a lot of data but only a few errors will be safe)
The algorithm property is essential for optimizing performance based on your specific use case and data characteristics.
Disk mode
The compare tool has two modes, it can store all its temporary files on disk or keep all in memory. By default, all is kept in memory. You can change this with the option "comparisonDataStorage", you can choose between the two following values: "InRam" and "OnDisk".
The InRam mode write only the report on disk, it’s quicker but if your data to compare are too big you need a lot of RAM. OnDisk mode is slower but you need less RAM
The option "comparisonDataStorage" must be set in the root part of the configuration file.
{
"comparisonDataStorage": "OnDisk",
"comparisonType": "Flatfile",
"flatfile": {}
} When OnDisk is chosen, additional properties shown in 5.6 can be used to customize the locations of the various temporary files: differencesFolder, leftCsvFolder and rightCsvFolder.
The files in these folders are temporary and discarded at the end of the comparison except if options keepDifferencesFiles and/or keepExtractedCsvs are set.
This means the ‘OnDisk’ mode may be used for performance reasons, but also for debugging purpose.
Html options
Report generation can also be RAM intensive if there is a lot of errors. Two options may be used in this case. "reportSplitLine" option will cut the details page of the report in several pages, adding an intermediate routing page. "maximumDifferences" will completely discard additional errors. The correct counts are retained but the details are not kept.
These options can be set in the root part of the configuration file
{
"comparisonType": "Flatfile",
"reportSplitLine": 500",
"maximumDifferences ": 5000
} For instance, in this case, the report for each compared element will have parts containing 500 rows, and no more than ten such parts, additional errors being discarded.
In case "reportSplitLine" is used and an intermediate routing page is generated, it looks like this:
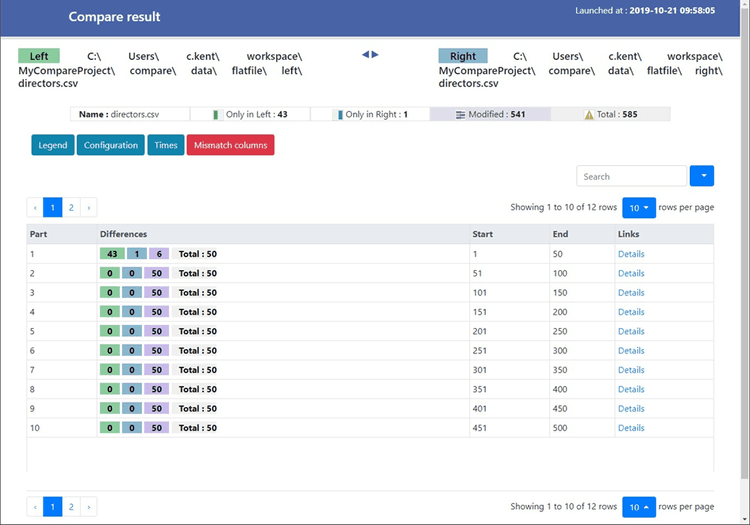
Please note that if the split options explained in Comparison performance are used, each split is considered a distinct element. Thus, the limits explained here will be for each split.
For instance, if you split comparison each 100 000 records and have 200 000 records, then you will have two comparison chunks, and each of these chunks may have a limit of 5000 differences.