In our ongoing efforts to enhance Blu Insights and uphold the highest standards, we have prioritized the improvement of our scaling system.
In our previous scaling system setup, we had to perform scale-in operations manually because the automated solutions lacked a feature to prevent terminating tasks with active workloads. However, with the introduction of ECS task scale-in protection, we now have the opportunity to automate scale-in operations.
In this article, we will share our approach to constructing our scaling system, using services such as ECS, Application Auto Scaling, and CloudWatch.
An Introduction to scaling
Scaling involves adjusting resources to maintain optimal performance. We can categorize scaling into two main types: vertical scaling and horizontal scaling.
Vertical scaling entails increasing or decreasing the power of your resources. For example, you might add more CPU to your server to boost computational power. We refer the act of enhancing computational power to as ‘scaling up’, while we define reducing computational power as ‘scaling down’.
On the other hand, horizontal scaling involves adding or removing instances, such as adding more servers to handle increased user demand. Adding instances is called ‘scaling out’, while we name removing instances as ‘scaling-in’.
In this article we will focus on the horizontal scaling.
How ECS performs Scaling
ECS is a service introduced by AWS to simplify running containers on EC2 instances. We can use the Fargate mode to avoid managing the EC2 instances. ECS can be used to run continuous workloads such as a web server, or running workloads such as jobs.
To perform scaling operations, ECS primarily relies on two services: CloudWatch and Application Auto Scaling.
- CloudWatch is a monitoring service that you can use for collecting logs, tracking metrics related to your application, and creating alarms.
- The Application Auto Scaling service is designed to automate the adjustment of resources, such as EC2 instances and DynamoDB tables, in response to changing application traffic or load. This ensures optimal performance and cost efficiency.
When using Application Auto Scaling, you need to define the scaling policy to use. You can choose from three options:
- Target Scaling Policy: This scales a resource based on a target value for a specific CloudWatch metric.
- Step Scaling Policy: This scales a resource based on a set of scaling adjustments that vary based on the size of the alarm breach.
- Scheduled Scaling: This allows you to scale a resource either one time or on a recurring schedule.
The diagram below highlights the scaling process using the target tracking scaling policy: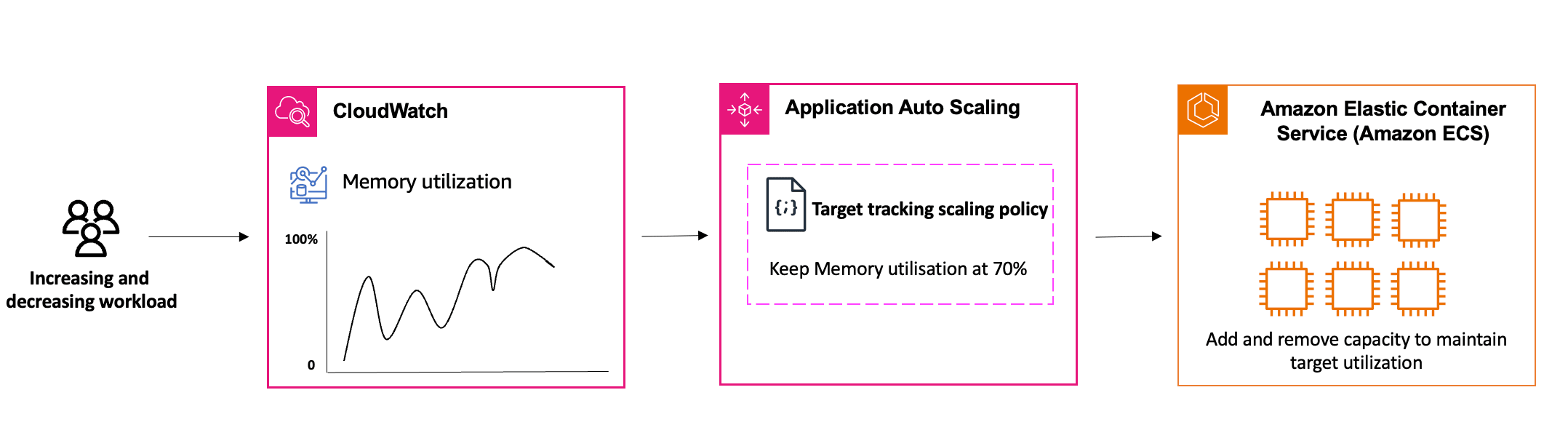
In the schema, changes in workload will affect our application’s memory utilization. The target tracking scaling policy defined in Application Auto Scaling ensures that our application maintains memory utilization at the target level of 70% by adding or removing capacity from ECS.
How we built the scaling system
Overview of the architecture
Before delving into the methodology we used, I will start by introducing a simplified version of our architecture: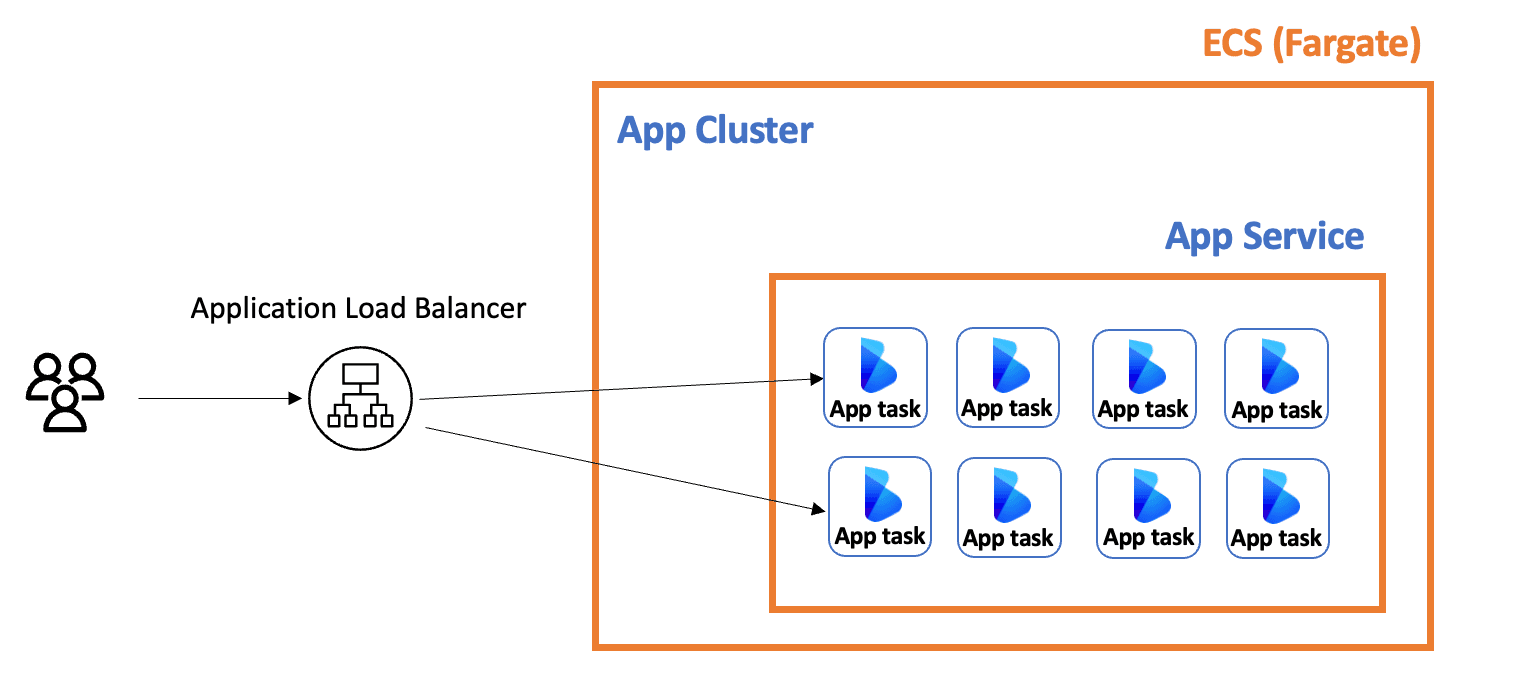 In this article, we will focus on the app cluster, as it’s the one for which we built the scaling system. The app cluster consists of a service that spans multiple app tasks. Each task is independent and capable of fulfilling user requests.
In this article, we will focus on the app cluster, as it’s the one for which we built the scaling system. The app cluster consists of a service that spans multiple app tasks. Each task is independent and capable of fulfilling user requests.
A load balancer is used to front our ECS cluster, distributing the load across multiple tasks. Additionally, we are utilizing Fargate to avoid managing the underlying EC2 instances.
How we built the scaling system
Based on our understanding of the scaling workflow in ECS and the services involved, we used the following methodology to build our scaling system: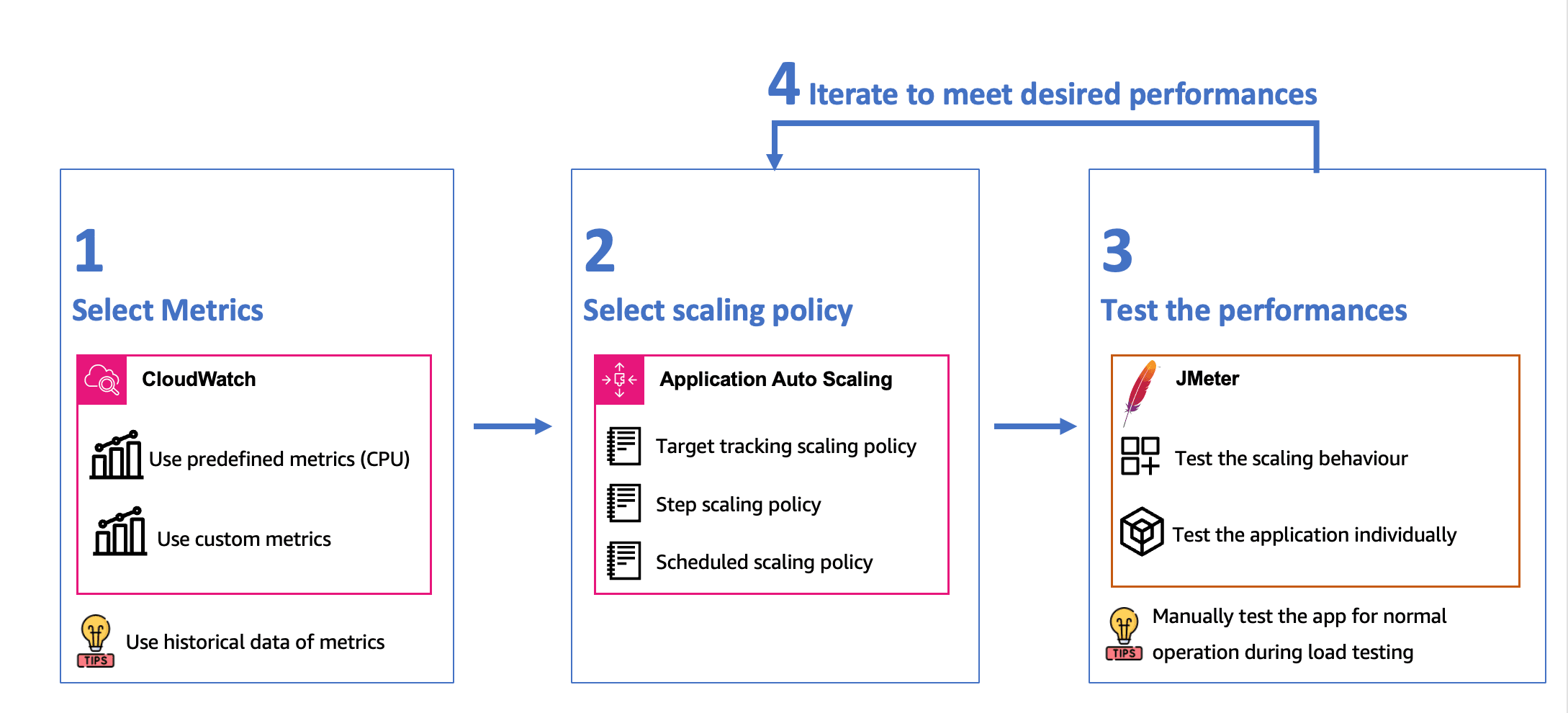
Step 1: Select Metrics
In this step, we choose the metrics that will drive our scaling decisions. It’s crucial to select metrics that directly affect the performance of our application.
We can either use predefined metrics from CloudWatch, such as CPU utilization, or create custom metrics tailored to our application.
To help decide which metrics to use, you can rely on the historical for more insights.
Step 2: Select Scaling Policy
In this step, we specify the scaling policies to be employed by Application Auto Scaling. You have the option to choose from three types of policies: Target Tracking Scaling, Step Scaling, and Scheduled Scaling.
Step 3: Test the Performances
In this step, we recommend conducting two types of tests:
- Individual performance testing of the application to understand peak performance and application limits.
- Testing the scaling behavior of the selected scaling policy. This testing provides insights into how quickly your system scales and responds to spikes in load.
Additionally, it’s beneficial to run manual tests to gauge the user experience.
Finally, we iterate between the second and third steps until we find the appropriate scaling policy for our application.
Building the scale out workflow
Based on the methodology defined in the previous section, we have selected the following elements to build our scale-out system: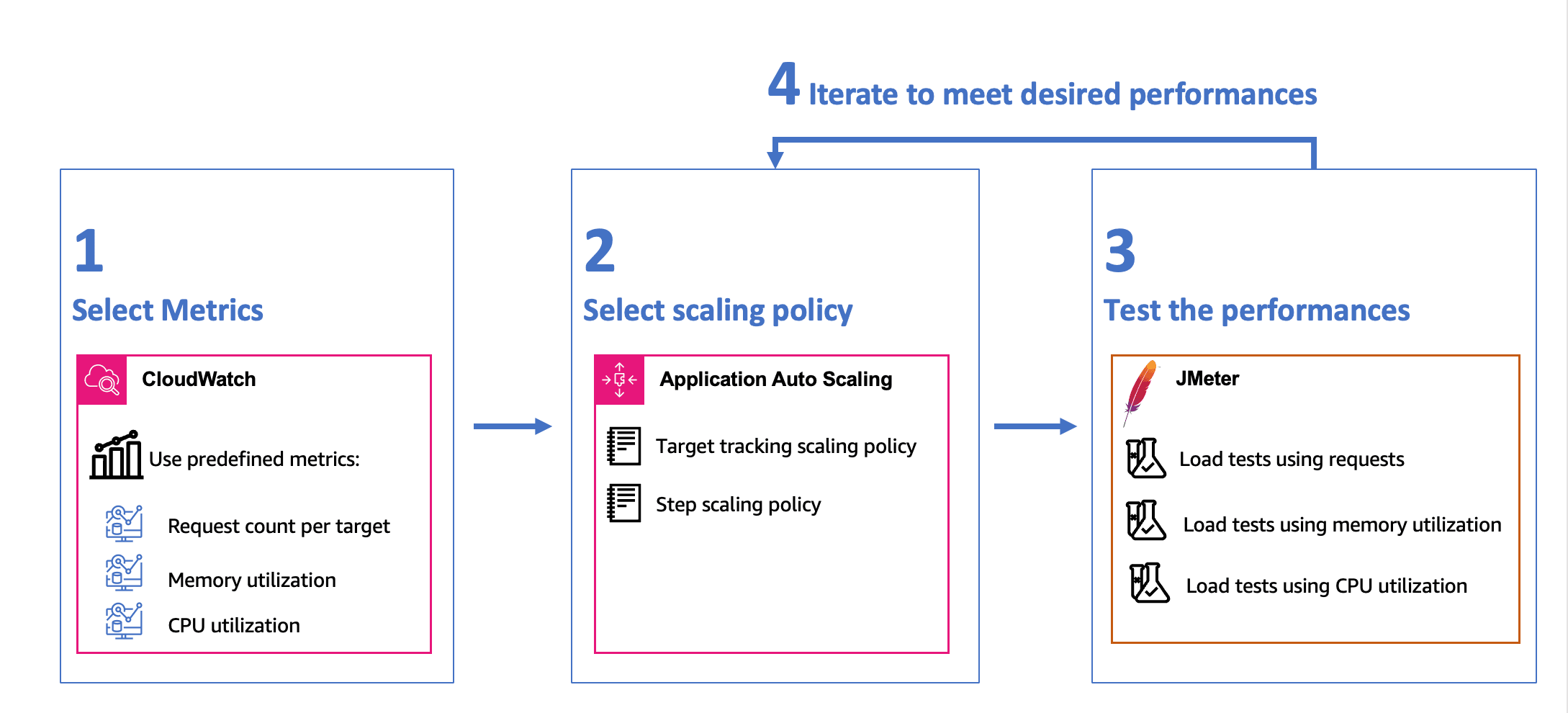
After conducting multiple rounds of testing with different scaling policies and parameters, we have reached the following conclusions:
- The target tracking scaling policy was not suitable for our needs. The scale-out process was slow, which posed a threat to the application’s stability. Also, we lacked control over the number of tasks added.
- Step scaling proved to be a faster alternative compared to target tracking. It provided us with complete control over the number of tasks we added. With step scaling, we gained complete control over the number of instances, which resulted in better handling of spikes.
Below, we outline our scale-in strategy with specific metrics and policies:
| Strategy | Metrics | Policy |
| Step Scaling | CPU utilization | > 60% add 1 task |
| > 70% add 3 tasks | ||
| Memory utilization | > 60% add 1 task | |
| > 70% add 3 tasks | ||
| Request count per target | > 600 req/min add 1 task | |
| > 700 req/min add 3 task |
Building the scale-in workflow
Similar to our approach for building the scale-out system, here are the elements we selected to build our scale-in system: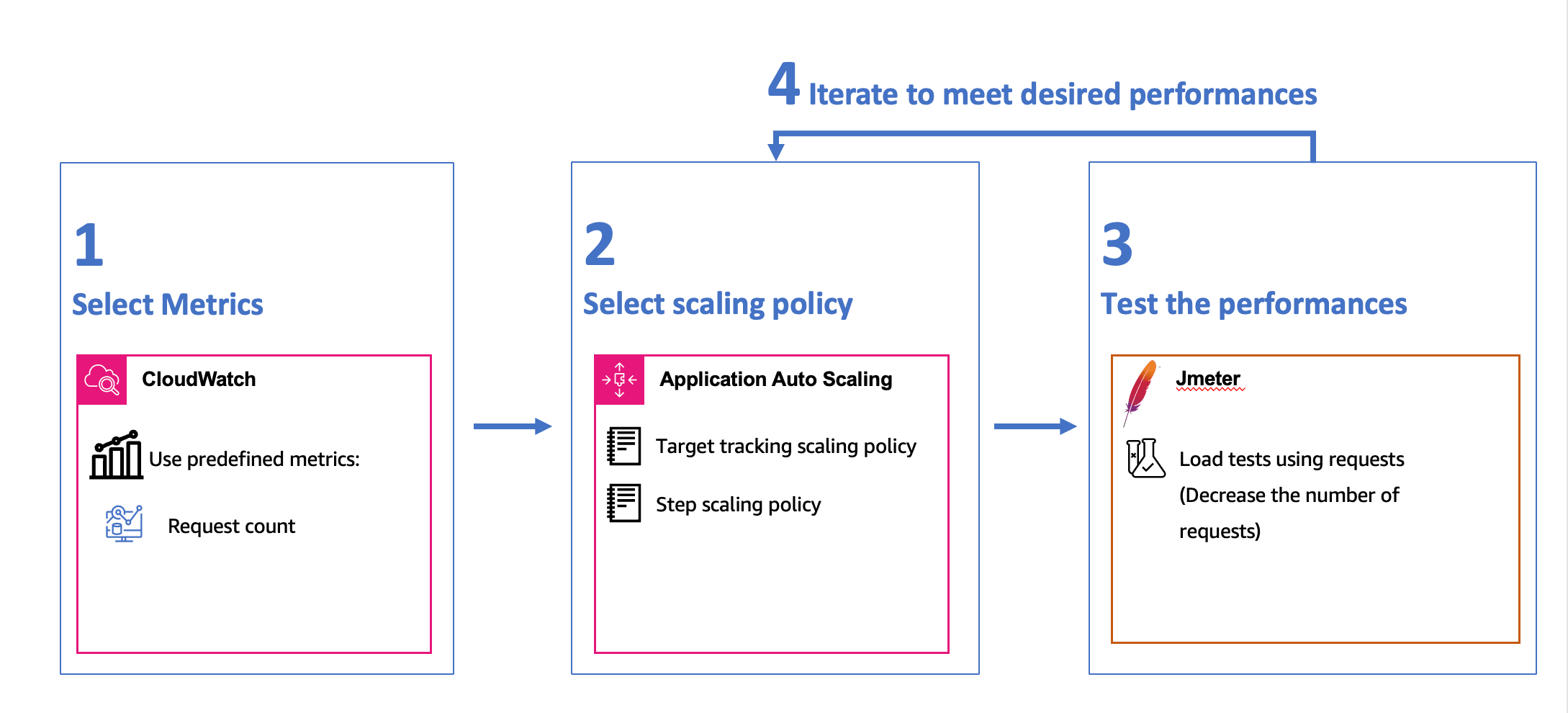
Please note that we chose to focus solely on the total request count. This decision is based on our performance tests during the scale-out phase and an analysis of historical data, which revealed that CPU and memory were not suitable metrics for scale-in.
After conducting multiple rounds of testing with different scaling policies and parameters, we have reached the following conclusions:
- The target tracking scaling policy was not suitable for our application. It proved to be slow, and we lacked control over the number of instances removed. Additionally, we encountered some 5xx errors.
- The Step scaling policy, on the other hand, was faster and provided us with complete control over the number of instances to be removed. However, it also encountered 5xx errors.
- The 5xx errors were the result of terminating tasks while running some workload during scale in events.
Below, we outline our scale-in strategy with specific metrics and policies:
| Strategy | Metrics | Policy |
| Step Scaling | Request count | Between 100 and 50 remove 2 tasks |
| Between 50 and 30 remove 4 tasks | ||
| Between 30 and 10 remove 8 tasks | ||
| Between 30 and 10 remove 16 tasks |
Protecting tasks during scale-in event
In the previous section, we encountered a problem where tasks were terminated while running workloads, leading to the occurrence of 5xx errors.
In this section, we will discuss the mechanisms we implemented to address this issue. However, before diving into our solutions, let’s first explore the existing options available for mitigating such behaviors.
When examining our architecture, two features introduced by AWS come to mind for handling these situations: Application Load Balancer Deregistration Delay and Task Scale-In Protection.
Application Load Balancer Deregistration
This process allows an Application Load Balancer to complete in-flight requests to instances being removed from service before fully deregistering them. It ensures a smooth transition, preventing sudden service interruptions when instances are taken out of the load balancer.
While this solution is effective for applications with light requests, it may have limitations for applications with longer requests. The first limitation is that the deregistration delay is limited to one hour, which is sufficient for most applications. However, the second drawback is that if your instance completes it’s in-flight request within the first 5 minutes, and you’ve set the deregistration delay for an hour, the instance won’t be removed from the target group until the delay expires. This can impact the instance’s lifecycle, leaving the task in a deactivating state until the end of the deregistration delay.
For our application, which includes long requests, using the deregistration delay is not suitable. We might have requests that span more than an hour, and setting a high value for the deregistration delay can leave our service with many tasks in the deactivating state, ultimately increasing our billing costs.
Task scale-in protection
Task Scale-In Protection is a feature designed to safeguard ECS tasks during critical workloads when a scale-in event occurs. To enable or disable this protection, you can use the SDK.
The following example illustrates how our service terminates tasks during a scale-in event without protection, resulting in random task terminations. 
The behavior of the scale-in event changes when task protection is enabled. In the diagram below, you can see that certain tasks are protected from termination during a scale-in event.  The task scale-in protection is an effective solution to avoid encountering 5xx errors, as it provides us with control over which tasks to terminate and when.
The task scale-in protection is an effective solution to avoid encountering 5xx errors, as it provides us with control over which tasks to terminate and when.
Implementing task protection for Blu Insights
To optimize how we use task scale-in protection in our application, we have introduced the following process to reduce the number of requests to ECS and track the workloads in progress.
Enabling Protection for a Task
Our mechanism for enabling task protection for a task takes into consideration the following cases.
Case 1: Protecting an unprotected task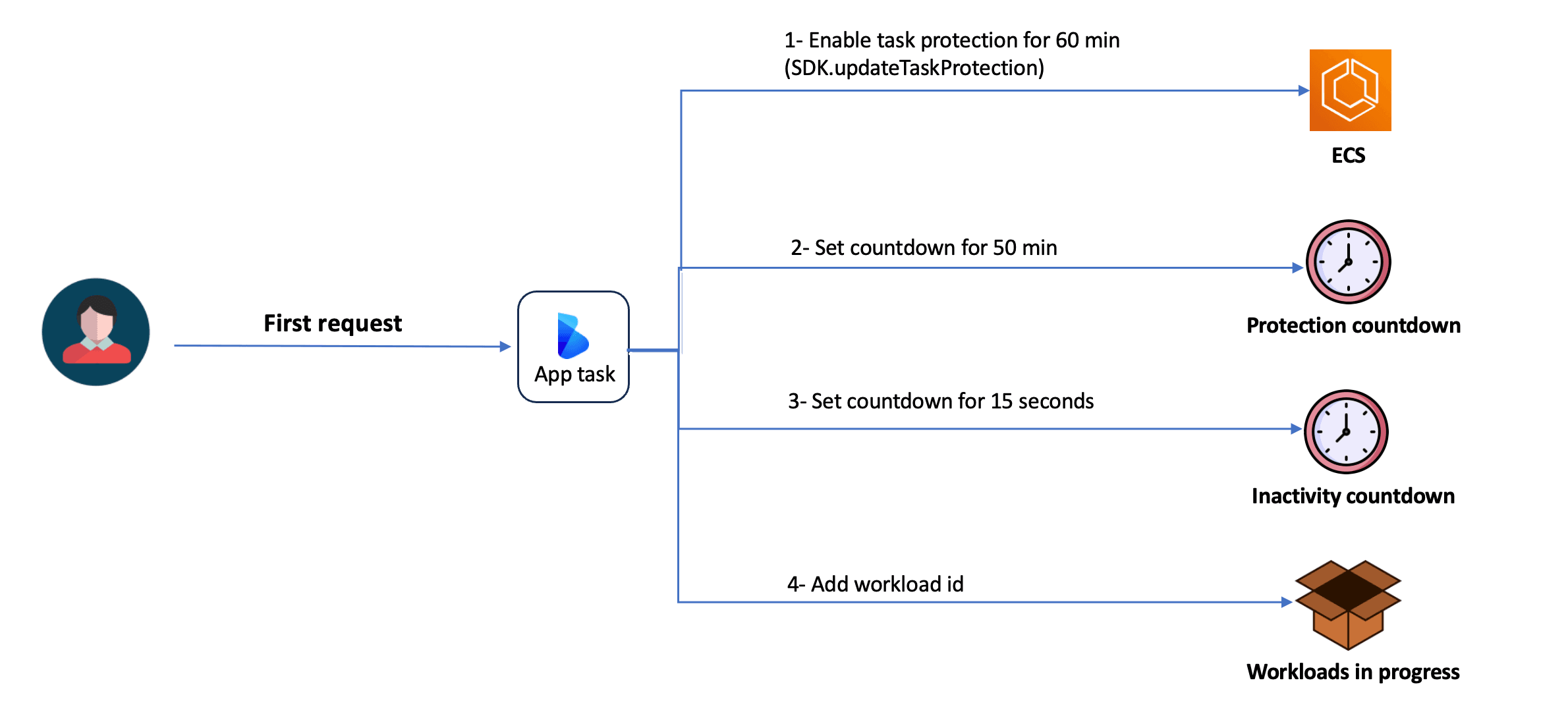
- Send an API call to ECS to enable task scale-in protection for one hour. Once ECS fulfills the request, the task becomes protected.
- Set a protection countdown for 50 minutes. This countdown is used to extend task protection.
- Set an inactivity countdown for 15 seconds. This countdown is used to disable task scale-in protection.
- Add the workload ID to the “workloadsInProgress” variable. This variable is used to track workloads in progress.
Case 2: Tracking workloads for a protected task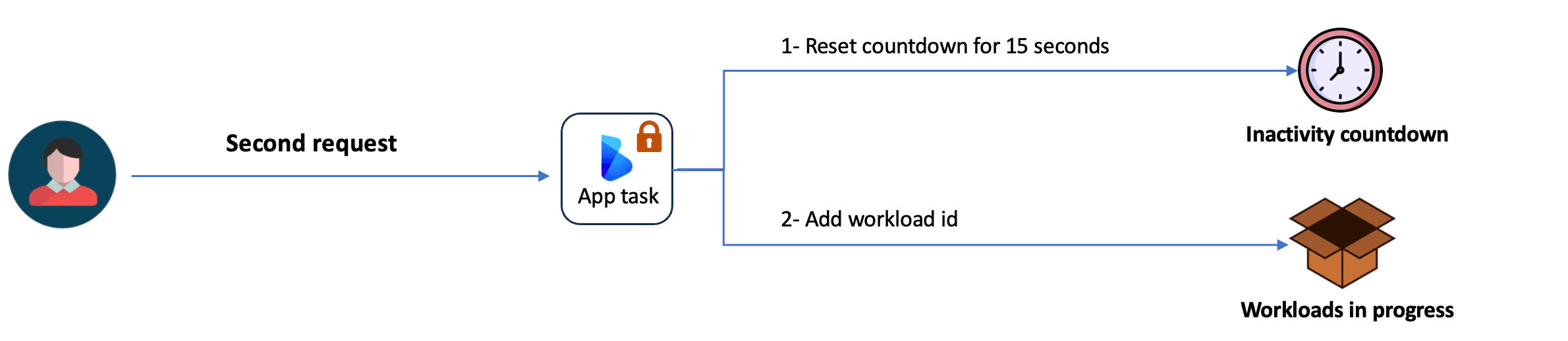
- Reset the inactivity countdown for an additional 15 seconds.
- Add the workload ID to the “workloadsInProgress” variable.
Case 3: Handling workload completion
- Remove the workload ID from the “workloadsInProgress” variable.
- Send a response to the client.
Disabling Protection for a Task
The process of disabling task protection is simple, as highlighted in the following diagram:
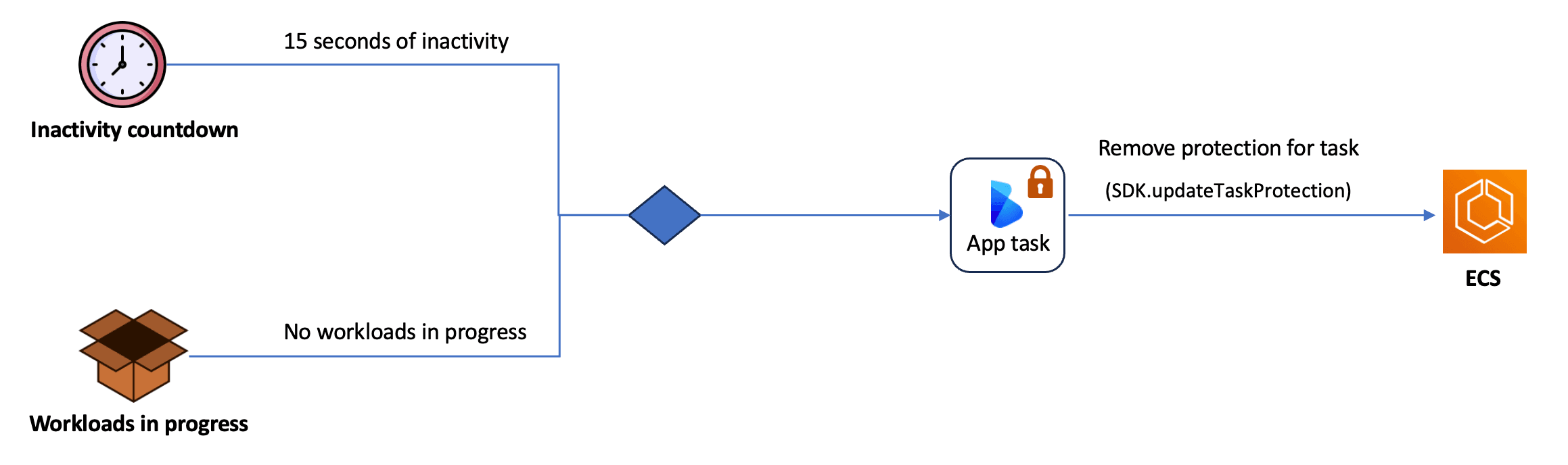
- To disable task protection, two conditions must be met: the task has been inactive for 15 seconds, and no workloads are in progress.
- Send an API call to ECS to disable task scale-in protection. Once ECS fulfills the request, the task becomes unprotected.
Task scale-in protection significantly reduced the number of 5xx errors we previously encountered. However, we noticed that there was an edge case leading to a small number of 5xx errors. In the next section, we will introduce this issue and the solution we deployed.
Customizing the scale-in process
In our scaling system development, we established suitable scaling strategies and ensured the protection of tasks against termination during scale-in events. However, during further testing, we discovered a rare but critical issue leading to occasional 5xx errors.
To understand the issue, let’s examine the scale-in workflow highlighted in the diagram below.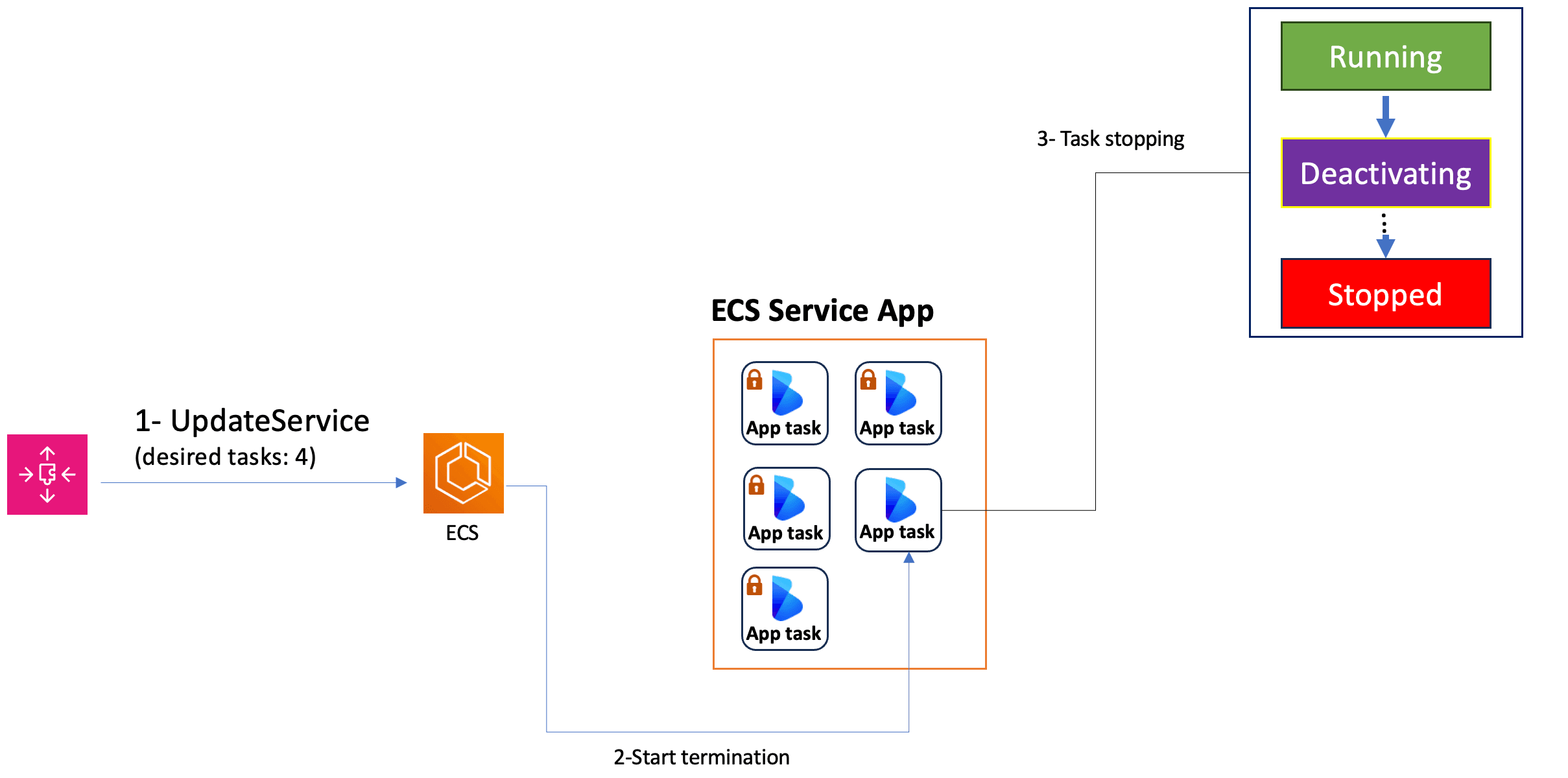
- Application Auto Scaling initiates a scale-in request, leading to the removal of one instance.
- ECS begins the termination process for the unprotected task.
- The task transitions through several states, from ‘Running’ to the last state ‘Stopped’:
- In the ‘Deactivating’ state, the instance is deregistered from the load balancer, which typically takes between 15 to 40 seconds for the task to complete.
- If the task receives a long request during this timeframe, the application terminates with a 5xx error. This occurs because the task transitions to the ‘Stopped’ state before it can finish processing the workload in progress.
In summary, the issue arises because the task continues to receive requests during its 'Deactivating' state.
Solution overview
To address this problem, we aim to prevent the load balancer from ceasing requests to the task before it reaches the 'Deactivating' state. Here's an overview of our solution: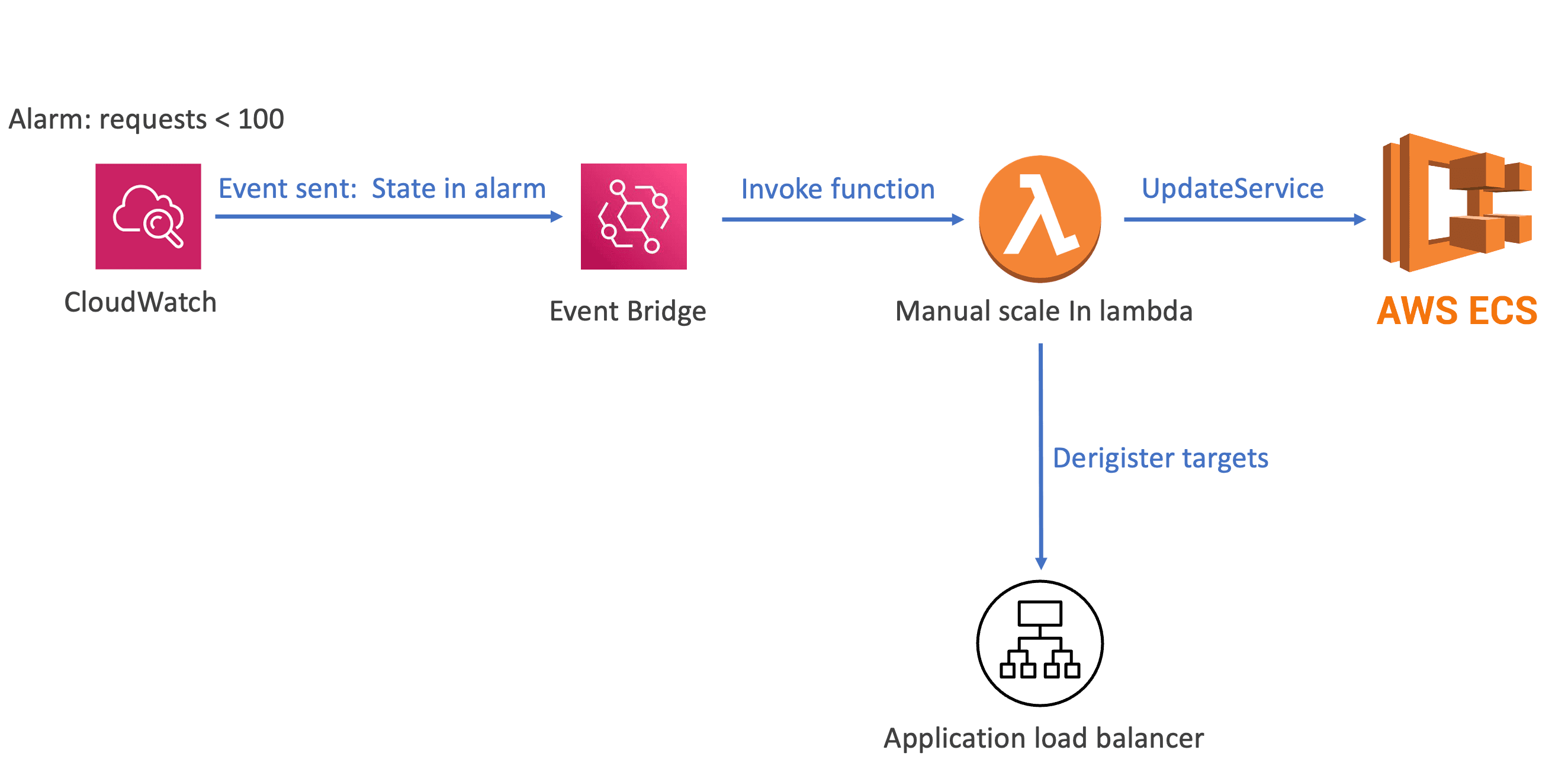
- We will configure a CloudWatch alarm to trigger when the request rate drops below 100 requests per minute.
- Next, we'll utilize the EventBridge service to detect the alarm-triggered event and invoke the Lambda function.
- The Lambda function will simulate the role of the Application Auto Scaling service. It will determine the tasks to be terminated while respecting the scale-in policy we introduced earlier and deregister them from the application load balancer.
- Furthermore, the Lambda function will initiate the scale-in operation by making an API call using 'updateService'.
Conclusion
In conclusion, building a scaling system may indeed pose its share of challenges, but AWS offers a diverse array of solutions aimed at simplifying the design and implementation of your scaling system.
Throughout the course of this article, we’ve taken you through our journey in crafting the scaling system for Blu Insights. We’ve delved into the methodology we adopted, the challenges we confronted, potential solutions we explored, and the successful strategies we embraced for our unique application.
While the Application Auto Scaling service is adept at meeting the requirements of the majority of applications, there may be instances where your use case demands a higher degree of customization. In such scenarios, AWS stands ready to empower you with the flexibility to construct a custom scaling system by using other AWS services.